

Создание кастомного распознания объектов с использованием YOLOv3 с ImageAI
Цель данной статьи помочь начинающему девелоперу в разработке своей системы обнаружения объектов, направляя на все ключевые моменты для обучения успешной модели.
Для примера будем тренировать модель с помощью ImageAI, а также открытой Python библиотеки которая разрешит Вам натренировать модель в пару строк кода.
Вступление
В данной статье мы рассмотрим все необходимые шаги в создании детектора изображений, от получения датасета до тестирования нашей модели.
Вот наши шаги:
- Сбор данных
- Разметка датасета
- Увеличение данных
- Тренировка модели
- Оценка модели
Сбор данных
Перед тем как мы начнем тренировать нашу модель мы должны собрать как можно больше данных, в нашем случае это изображения. Минимум должно быть 200 изображений в зависимости от сложности нашего детектора.
Если мы хотим что б наша модель была максимально надежна, наши изображения должны отличатся друг от друга освещением и фоном, что бы наша модель могла делать лучше выводы.
Эти изображения могут быть сделаны на ваш телефон или скачены с интернета.
Тут вы можете увидеть мой под-датасет распознания пилюль.
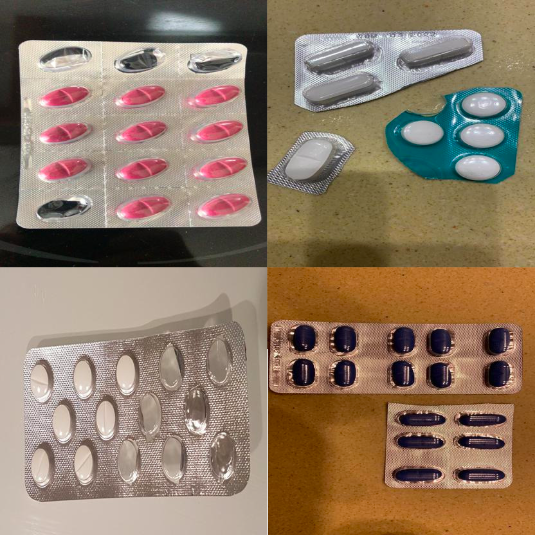
После получения дадасета мы должны обрезать наши изображения, потому что некоторые из них имеют большой размер. Маленький размер фото означает что наша модель будет работать быстрее.
Для этого я написал следующий скрипт:
import os
from PIL import Image
# Define here your paths
original_images_path = '...'
resized_images_path = '...'
new_width = 416
new_height = 416
for image_file in os.listdir(original_images_path):
ima = Image.open(original_images_path + image_file)
new_ima = ima.resize((new_width, new_height), Image.ANTIALIAS)
new_ima.save(resized_images_path + image_file)
Разметка данных
Это самы утомительный этап, поскольку вы должны разметить каждый простой объект который вы хотите чтоб модель распознала.
Вы можете разметить ваши изображения с помощью LabelImg. Запустите следующую команду в терминале для установки.
pip3 install labelImg
После установки вы можете приступать к разметки фотографий выполнив команду.
labelImg path_to_images/
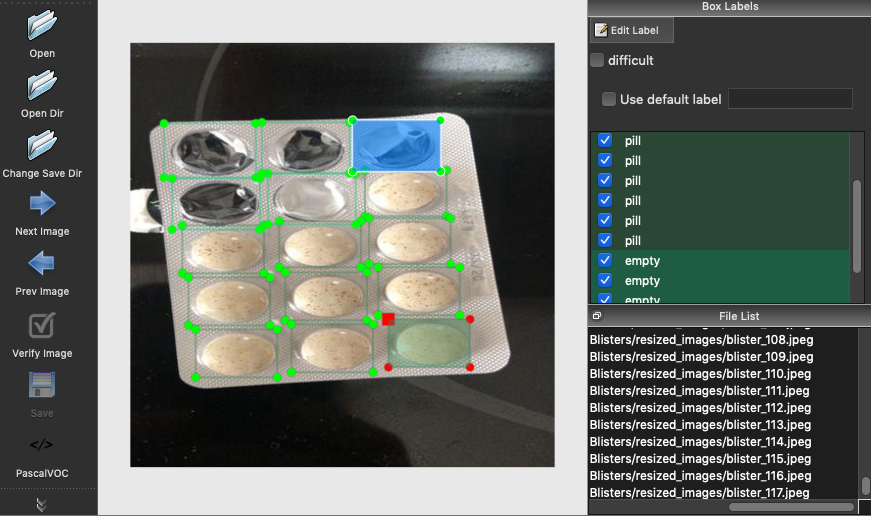
Затем вам нужно создать прямоугольную рамку с соответствующей меткой, для каждого объекта на изображении.
После разметки всех объектов на изображении вы должны сохранить в PascalVOC формат генерируемый .xml файл
Увеличение данных
Наличие большого набора данных имеет решающее значение для производительности нашей модели глубокого обучения, поэтому мы можем дополнить данные, которые у нас уже есть, с помощью библиотеки imgaug.
Этот github репозиторий объясняет и предоставляет код как дополнить изображения данными из размеченных прямоугольников. Этот процесс можно описать тремя этапами:
- Конвертация .xml файл в .csv формат
- Применить дополненные данные
- Конфертировать результирующий .csv файл в множество .xml файлов
Сперва мы определим ф-ю конвертации наших .xml файлов в .csv
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height',
'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
Затем мы определим функцию обратного процесса.
import csv
import xml.etree.cElementTree as ET
def csv_to_xml(csv_path, resized_images_path, labels_path, folder):
f = open(csv_path, 'r')
reader = csv.reader(f)
header = next(reader)
old_filename = None
for row in reader:
filename = row[0]
if filename == old_filename:
object = ET.SubElement(annotation, 'object')
ET.SubElement(object, 'name').text = row[3]
ET.SubElement(object, 'pose').text = 'Unspecified'
ET.SubElement(object, 'truncated').text = '0'
ET.SubElement(object, 'difficult').text = '0'
bndbox = ET.SubElement(object, 'bndbox')
ET.SubElement(bndbox, 'xmin').text = row[4]
ET.SubElement(bndbox, 'ymin').text = row[5]
ET.SubElement(bndbox, 'xmax').text = row[6]
ET.SubElement(bndbox, 'ymax').text = row[7]
else:
if old_filename is not None:
labels_file = old_filename.replace('.jpg', '.xml')
tree = ET.ElementTree(annotation)
tree.write(labels_path + labels_file)
annotation = ET.Element('annotation')
ET.SubElement(annotation, 'folder').text = folder
ET.SubElement(annotation, 'filename').text = filename
ET.SubElement(annotation, 'path').text = resized_images_path + filename
source = ET.SubElement(annotation, 'source')
ET.SubElement(source, 'database').text = 'Unknown'
size = ET.SubElement(annotation, 'size')
ET.SubElement(size, 'width').text = row[1]
ET.SubElement(size, 'height').text = row[2]
ET.SubElement(size, 'depth').text = '3'
ET.SubElement(annotation, 'segmented').text = '0'
object = ET.SubElement(annotation, 'object')
ET.SubElement(object, 'name').text = row[3]
ET.SubElement(object, 'pose').text = 'Unspecified'
ET.SubElement(object, 'truncated').text = '0'
ET.SubElement(object, 'difficult').text = '0'
bndbox = ET.SubElement(object, 'bndbox')
ET.SubElement(bndbox, 'xmin').text = row[4]
ET.SubElement(bndbox, 'ymin').text = row[5]
ET.SubElement(bndbox, 'xmax').text = row[6]
ET.SubElement(bndbox, 'ymax').text = row[7]
old_filename = filename
f.close()
Затем мы определим наш данные с imgaug, для примера напишем следующее
from imgaug.augmentables.bbs import BoundingBoxesOnImage
from imgaug import augmenters as iaa
aug = iaa.SomeOf(2, [
iaa.Affine(scale=(0.5, 1.5)),
iaa.Affine(rotate=(-60, 60)),
iaa.Affine(translate_percent={"x": (-0.3, 0.3), "y": (-0.3, 0.3)}),
iaa.Fliplr(1),
iaa.Multiply((0.5, 1.5)),
iaa.GaussianBlur(sigma=(1.0, 3.0)),
iaa.AdditiveGaussianNoise(scale=(0.03 * 255, 0.05 * 255)),
iaa.Add((-25, 25)),
iaa.MotionBlur(k=15),
iaa.MultiplySaturation((0.5, 1.5)),
iaa.LogContrast(gain=(0.6, 1.4)),
iaa.Flipud(1)
])
В завершение применим этот пайплайн к нашему датасету и сохраним оба дополнительных изображения и их дополнительные метки. Вы также должны определить функции image_aug() и bbs_obj_to_df(), которые лежат в данном репозитории github.
if __name__ == '__main__':
xml_df = xml_to_csv('labels_path/')
for i in range(10):
augmented_images_df = image_aug(xml_df, 'resized_images/', 'resized_images/', 'aug{}_'.format(i), aug)
augmented_images_df.to_csv('aug{}_images.csv'.format(i), index=False)
csv_to_xml(csv_path='aug{}_images.csv'.format(i),
resized_images_path='resized_images/',
labels_path='labels_path/',
folder='resized_images')
os.remove('aug{}_images.csv'.format(i))
Тренинг модели
После всего этого препроцессинга мы наконец можем обучить нашу модель с помощью ImageAI.
Прежде всего нужно установить библиотеку.
pip3 install imageai
Для использования трансферного обучения вы можете скачать модель отсюда.
Затем нам нужно разделить наш набор данных на папки train и validation.
dataset
├─ train
│ └── images
│ └── annotations
└─ validation
├── images
├── annotations
Это можно сделать с помощью следующего кода.
import os
import shutil
import random
images_path = 'resized_images/'
labels_path = 'labels/'
train_path = 'dataset/train/'
validation_path = 'dataset/validation/'
for image_file in os.listdir(images_path):
labels_file = image_file.replace('.jpg', '.xml')
if random.uniform(0, 1) > 0.2:
shutil.copy(images_path + image_file, train_path + 'images/'
+ image_file)
shutil.copy(labels_path + labels_file, train_path +
'annotations/' + labels_file)
else:
shutil.copy(images_path + image_file, validation_path +
И мы можем начать тренировку с помощью следующего сценария.
from imageai.Detection.Custom import DetectionModelTrainer trainer = DetectionModelTrainer() trainer.setModelTypeAsYOLOv3() trainer.setDataDirectory(data_directory="your_dataset_path") trainer.setTrainConfig(object_names_array=["obj1", "obj2"], batch_size=16, num_experiments=200, train_from_pretrained_model="pretrained-yolov3.h5") trainer.trainModel()
Оценка модели
После того как мы обучили нашу модель, мы можем оценить каждый чекпоинт обучения через mAP.
from imageai.Detection.Custom import DetectionModelTrainer trainer = DetectionModelTrainer() trainer.setModelTypeAsYOLOv3() trainer.setDataDirectory(data_directory="dataset") metrics = trainer.evaluateModel(model_path="dataset/models", json_path="dataset/json/detection_config.json", iou_threshold=0.5, object_threshold=0.9, nms_threshold=0.5)
Вывод должен выглядеть примерно так.

Используем нашу модель для обнаружения
Наконец, мы можем использовать нашу модель для обнаружения объектов на одном изображении.
from imageai.Detection.Custom import CustomObjectDetection
detector = CustomObjectDetection()
detector.setModelTypeAsYOLOv3()
detector.setModelPath("detection_model-ex-006--loss-0024.905.h5")
detector.setJsonPath("detection_config.json")
detector.loadModel()
detections = detector.detectObjectsFromImage(input_image="ima.jpg", output_image_path="ima-detected.jpg", minimum_percentage_probability=90)
view raw
Вы можете настроить параметр Minim_percentage_probability, чтобы показать обнаруженные объекты с большей или меньшей достоверностью, получив результат, подобный следующему.

Теперь я хотел бы услышать от вас, как это работает!
Спасибо за прочтение!
Перевод статьи, источник.
